Understanding Tokenization Drift: Causes and Solutions for Reliable AI Model Behavior
What Is Tokenization Drift?
Imagine your AI model performing flawlessly on a task one moment, then delivering erratic or degraded results the next—without you changing a single line of code, data, or pipeline. The culprit is often not a bug in your logic, but something far more subtle: how your input text is tokenized. Before a large language model (LLM) can process text, it converts words into numerical token IDs. Even trivial formatting differences—such as extra spaces, line breaks, or punctuation shifts—can produce entirely different token sequences. This phenomenon is known as tokenization drift: when minor surface-level changes push your input into a different region of token space, causing unpredictable shifts in model behavior.
Why Tokenization Drift Matters
The impact goes deeper than just token IDs. During instruction tuning, models learn not only the tasks themselves but also the structural patterns in which those tasks are presented—specific separators, prefixes, and formatting conventions. When your prompt deviates from these learned patterns, the model is no longer operating within its familiar distribution. The result isn't confusion; it's the model doing its best on inputs it was never optimized to handle. This can lead to inconsistent outputs, reduced accuracy, and unpredictable behavior in production systems.
Demonstrating Tokenization Drift with GPT-2
To see tokenization drift in action, we'll use the GPT-2 tokenizer—a Byte-Pair Encoding (BPE) scheme that is architecturally identical to those used by GPT-4, LLaMA, and Mistral. GPT-2 is chosen because it requires no authentication and clearly exhibits the space-prefix artifact found in all modern production tokenizers. Follow along with the code below.
Setting Up the Tokenizer
First, install the required libraries and load the tokenizer:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import seaborn as sns
from collections import defaultdict
from sklearn.decomposition import PCA
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
print("Tokenizer loaded:", tokenizer.__class__.__name__)
print("Vocab size:", tokenizer.vocab_size)The Space-Prefix Artifact
We take seven common words and test each in two forms: once with a leading space and once without. By setting add_special_tokens=False, we ensure we only measure the token IDs for the words themselves, without extra padding or markers.
words = ["classify", "token", "model", "text", "input", "output", "data"]
for word in words:
tokens_no_space = tokenizer.encode(word, add_special_tokens=False)
tokens_with_space = tokenizer.encode(" " + word, add_special_tokens=False)
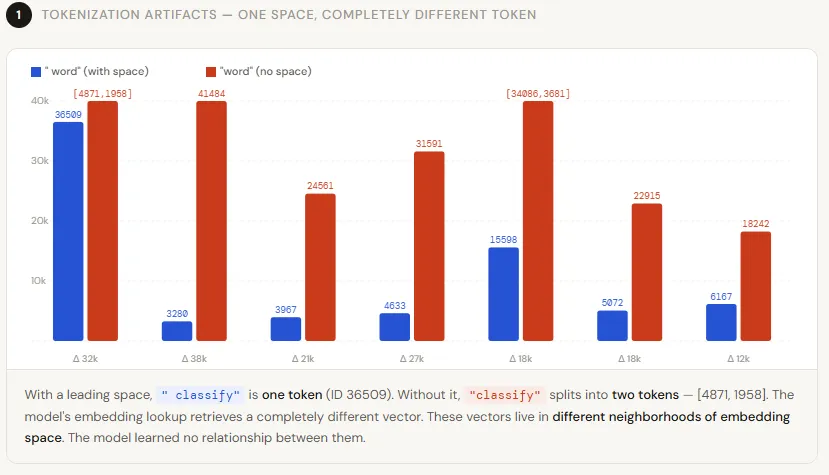
print(f"'{word}' -> {tokens_no_space}, ' {word}' -> {tokens_with_space}")The results are striking. Not a single pair produces the same token ID—every word is treated as completely different depending on whether it has a leading space. Even more interesting, some words without the space don't map to a single token at all. For example, classify becomes two tokens [4871, 1958], while classify is a single token [36509]. This means the model doesn't just see a different ID—it sees a different sequence length, which shifts how attention is computed for everything that follows.
Measuring Drift
To quantify tokenization drift, we can build a simple metric that compares token sequences across different prompt formats. One approach is to encode a set of prompts that vary only in formatting (e.g., with or without whitespace, different separators), then compute the cosine similarity between their token embedding vectors (obtained from the model's embedding layer). Another method involves using PCA to visualize the token distributions in a lower-dimensional space, making it easy to spot clusters that form due to formatting artifacts. By measuring how far the token representations deviate from a reference prompt, you can flag inputs that are likely to cause unexpected behavior.
Mitigating Tokenization Drift
Once you can measure drift, the next step is to control it. A lightweight prompt optimization loop can automatically select the formatting that keeps your inputs consistent and reliable. For instance, you can generate multiple variations of a prompt template (e.g., with and without leading spaces, different line breaks) and pick the one that minimizes the distance to a stable baseline. This approach ensures that your deployed models receive inputs aligned with their training distribution, reducing drift-induced performance drops.
Here's a conceptual outline of such a loop:
- Define a reference prompt that matches the format used during instruction tuning.
- Generate candidate prompts with small formatting variations (space prefixes, tab separators, etc.).
- Encode each candidate using the same tokenizer.
- Compute the drift metric for each candidate relative to the reference.
- Select the format with the lowest drift (or highest similarity).
By integrating this optimization into your preprocessing pipeline, you can dramatically reduce the variability introduced by tokenization drift.
Conclusion
Tokenization drift is a silent threat to LLM reliability. Even when your data and logic remain unchanged, trivial formatting changes can push inputs into unfamiliar token space, causing unpredictable model behavior. By understanding the space-prefix artifact and using simple measurement and mitigation techniques, you can ensure that your models see consistent, drift-free inputs. Start auditing your prompt formats today—your model's performance may depend on it.